趁著在家養傷 (腳痛) 寫程式的時候,順便把這陣子 PIXNET 在重新改寫的部份紀錄下來,從底層與 OS 比較有關的、PHP 的,以及 Web UI 的部份。
FreeBSD 的 NFS client 的效能並不好,在這次 PIXNET 前後台大改版前,我這幾天重新跑數據看目前舊系統的架構,可以看出來 PHP code 放到 NFS 上面所吃的 system CPU resource 比 userland CPU resource 還多:(這是其中一台 blog 主機的 CPU usage,用 Munin 畫出來的圖,中間斷掉那段是我在改 Munin 的設定...)
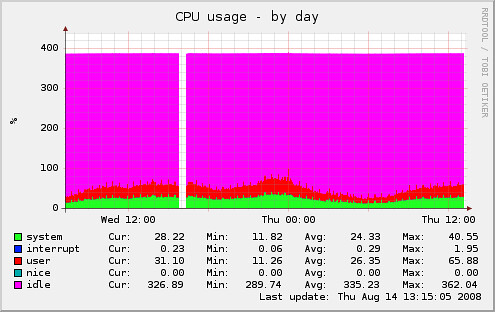
從圖上可以看出這台跑 blog 的主機有 4 Logical CPUs,但卻有很多 idle time。這是因為 NFS 量更大時會不穩定,所以我們無法使用更高。這次改版把所有的 code 都放到 local disk 上,應該會有很大的改進。
MySQL 還是用 Linux 比較好,同一台機器 (Xeon E5405 + 16GB RAM + 10KRPM*2) 分別跑過 FreeBSD 7-STABLE、8-CURRENT (20080812)、Linux 2.6。在 FreeBSD 上用 UFS2 (包括 noatime + async 與 noatime + softupdate 都有測試) 一直都是 I/O bound,而在 Linux 上用 XFS 一直都很順。這是用 MySQL slave 跑 real traffic 而非模擬測試。
新的資料庫系統還是用 Linux 平台,然後引入 DRBD 與 InnoDB 達到 High Availibility。不過我想在這陣子忙完後測 MMM,以他的實做方式看起來會比 DRBD 好。(但 DRBD 開發比較久,資料比較豐富,也比較容易找到穩定的設定)
PHP 的部份仍然使用 Apache 2.2 + mod_fastcgi 與 PHP。不過這次不跑 event mode,而是跑 worker (threading mode)。在正確的設定下,APC 的 cache 是整台機器共用,使用的記憶體更省。上面是 blog2 (worker MPM),下面是 blog5 (event MPM) 的記憶體使用量:(附註:我覺得 event 應該也可以做到同樣的事情,這次換 worker 是因為種種機緣 XD)
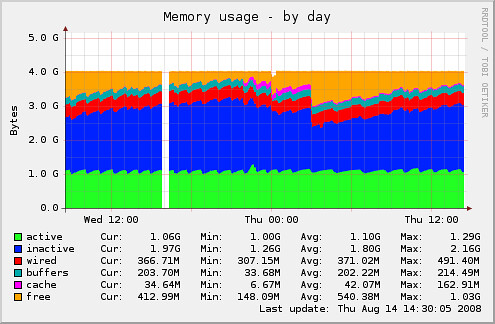

其中 FreeBSD 上可用記憶體空間的意義可以參考 Inactive memory 這篇,並不是只有 Free 代表可用空間。
靜態檔案在重新建立架構時,儘量拆開到其他 domain 上,除了可以 pipeline download,也可以節省使用者送 cookie 的頻寬,這部份的伺服器改用 nginx,因為要用他的 gzip on the fly 讓下載的量減少。我們用到的 javascript framework 盡量都塞進這個系統裡。
PHP 的部份,這次是賭了一把,選擇 Zend Framework 實做前後台,而且完完全全使用 ORM framework 處理資料。以目前的量去推算,看起來應該是沒問題,不過還沒上線前誰都不敢說,換燈管的 CTO 還為此先準備另外的機器,如果真的不行就用先暫時用機器海換出來...
我們用到的部份包括 Zend_Controller、Zend_View、Zend_Feed。(不,我們沒有用 Zend_Db,而是有個撞到腦袋的人寫了 Pix_Table_Cluster...)
不過 Zend_Controller 並不好用,沒有針對開發者的想法發展 (另外一種說法是,沒有針對 PHP 語言特性實做簡潔有力的語法),所以之後可能會自己開發 Pix_Controller。舉兩個例子說明:
- 要抓參數可以用 $this->getRequest()->getParam() 抓,也可以用 $this->_getParam() 抓。我可以理解後面是前面的捷徑,但如果 implements ArrayAccess 不是更好嗎?$this->getRequest() 抓出來的 object 可以直接 $obj['blog'] 抓出 blog 這個變數。
- 如果我想把 /foo/bar/12/34/56/78 拆開,我必須用 Route 做,然後再用 getParam 抓到參數。或是在 barAction 裡面直接自己拆開。我個人比較偏好的方法是先去找 bar_12_34_56_78_Action,沒有再一路往上找,最後會是 bar_Action('12', '34', '56', '78'),這樣寫 code 才會方便。
- 對 Helper 的使用相當不方便,但這個部份還沒有仔細想要怎麼做才會方便。
另外一個沒有用的是 Zend_Form,原因在於 Zend_Form 的預設值會使得客製化很困難。所以我們自己開發了 Pix_Form,只產生個別的元件,而不產生整體的 Form,所以你可以拿到一個版面後套版進去用。但仍然可以用 Pix_Form validate。
Deploy PHP code 的事情,目前是用 rsync 做,但 rsync 的效率並不高 (不過目前是夠用了),只能加減請 coder 擔待點。前陣子找了不少這類軟體在測試,像是 csync2,不過他同步的方式與期望了方式有落差,也許改變流程,配合 csync2 的方式做,或者是不改變流程,自己從頭幹一個出來?
Web UI 的部份這次改寫時直接強迫大家裝 Html Validator 直接檢查。我對 XHTML 1.0 沒有什麼好感 (事實上這次改版大多都是用 HTML 4.01),但至少不要有 <div> 不對稱這類 browser 會亂猜一通的問題。這樣才不用在奇怪的 DOM tree 裡面操作。
在政策上,javascript 全部用 jQuery,目前的 javascript code 幾乎都是 jQuery 寫出來的。Unobtrusive Javascript 目前只是個理想,有很多地方還是得直接處理。
另外就是 CDN 的事情,有機會再說 orz